fuse*
Series
Live performance
Artworks
Exhibitions
Agenda
Studio
Archive (beta)
Order by
Featured
[ Featured ]
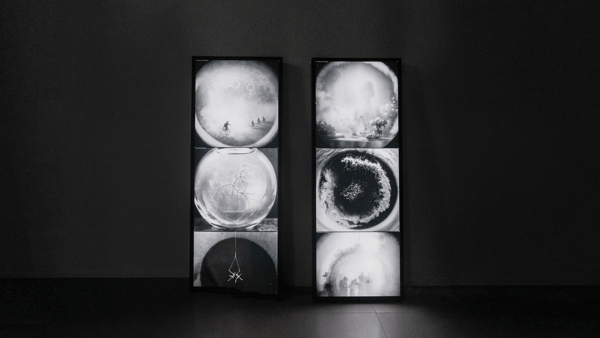
Onirica ()
2023
Luna Somnium
2022
Trust
2022
Artificial Botany .erbario assoluto
2023
Artificial Botany .morphos III
2021
Multiverse
2018
Onirica ()
Onirica ()
2023
Onirica () .solo
2023
Onirica ()
2024
Onirica () .lightbox
2023
Onirica () .lucid
2024
Onirica () .atlas
2024
Artificial Botany
Artificial Botany .erbario assoluto
2023
Artificial Botany .morphos III
2021
.morphos Seed0954
2022
.morphos Seed6322
2021
.herbarium Seed1010
2022
.morphos Seed1273
2022
.morphos Seed1252
2022
.morphos Seed1067
2022
.morphos Seed6095
2022
.morphos Seed6188
2022
.morphos Seed6042
2022
.aldrovandi Seed0385
2022
.aldrovandi Seed0579
2022
.aldrovandi Seed0242
2022
Artificial Botany .phase
2022
Artificial Botany .flow II
2022
Artificial Botany .flow III
2022
Artificial Botany .morphos XI
2023
.herbarium Seed4069
2022
.morphos Seed0292
2022
.morphos Seed6010
2022
.morphos Seed6391
2022
Artificial Botany .stream
2022
Unseen Flora
Unseen Flora .morphos IV
2024
Unseen Flora .BH03
2024
Unseen Flora .CB03
2024
Unseen Flora .150
2023
Unseen Flora .TW02
2024
Unseen Flora .CB02
2024
Unseen Flora .BH02
2024
Unseen Flora .ET02
2024
Unseen Flora .BH01
2024
Unseen Flora .TW01
2024
Unseen Flora .ET01
2024
Luna Somnium
Luna Somnium
2022
Luna Somnium .dome
2023
The Full Circle Trilogy
Sál
2025
Dökk
2017
Ljós
2014
Stigmergy
2018
Dökk .Vinyl
2018
Ljós .Vinyl
2015
Sál .Rite
2021
Mimicry
Mimicry
2025
Multiverse
Multiverse
2018
Multiverse .pan
2019
Multiverse .dome
2023
Multiverse .echo
2023
Growing Universes (S)
2018
Multiverse [Solid]
2021
Homeostasis [trial #1]
2021
Homeostasis [trial #2]
2022
Trust
Trust
2022
Treu
2020
Trust [Future Archives]
2022
Trust [Fragments]
2022
Trust [Atlas]
2022
AMYGDALA
AMYGDALA
2016
AMYGDALA .N
2022
Fragile
Fragile
2021
Mimesis
Mimesis
2020
Falin Mynd
Falin Mynd
2020
Clepsydra
Clepsydra
2016
Cortex
Cortex
2016
N
N
2010
N 4.0
2011
Snowfall
Snowfall
2009
Independent Frequencies
Independent Frequencies
2014
Fragments
Fragments
2013
Van Gogh in Me
Van Gogh in Me
2022